Goals:
To learn about 1) basic principles of the XML (eXtensible Markup Language) and its flavors (mainly, TEI), as well as its advantages and disadvantages; 2) ways of manipulating data in this format.
Software & Technologies:
python(simple scripting, regular expressions, batch processing)- XML
Class:
The Essence
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
XML & HTML
(NB: Not an exhaustive list, but rather a nudge to get you thinking in the right direction; for more: http://www.xmlobjective.com/what-is-the-difference-between-xml-and-html/)
- XML was designed to carry data—with focus on what data is
- HTML was designed to display data—with focus on how data looks
- XML tags are not predefined like HTML tags are
DOM (Document Object Model)
<TABLE>
<TBODY>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</TBODY>
</TABLE>
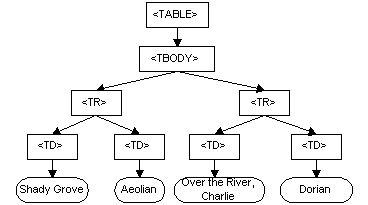
(more on DOM: https://www.w3.org/TR/DOM-Level-2-Core/introduction.html)
- If you have a well-formed XML/HTML document, you can use DOM to interact with the data in your file (for more on this, see additional tutorials in Reference materials on
Beautiful SoupandXSL(T)) - If you do not (a more real-life story), you need to use a different approach.
Looking for relevant patterns in file structure
- identify patterns around relevant data
- extract/split with
regular expressionsand a python script - convert into a clean test or simpler/more consistent format
Python code elements for the task
Regular Expressions Examples
import re
text0 = """
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
"""
# EXAMPLE 1 - find/replace
text = re.sub("<[^<]+>", "", text0)
print(text)
# EXAMPLE 2 - split
results = re.split("</[^<]+>", text0)
for r in results:
print(r)
print(results)
# EXAMPLE 3 - capture
text = re.search(r"<from>([^<]+)</from>", text0).group(1)
print(text)
Open/Save a file
with open(fileName, "r", encoding="utf8") as f1:
data = f1.read()
...
# dataNew = [transformations of data]
...
newFileName = fileName + "_modified.xml"
with open(newFileName, "w", encoding="utf8") as f9:
f9.write(dataNew)
Getting all files form a folder
import os
liftOfFiles = os.listdir(pathToFolder)
Magic Loop
for f in lof:
print(f) # for just a fileName
print(pathToFolder+f) # for full path
Reference Materials:
- On TEI XML: http://www.tei-c.org/release/doc/tei-p5-doc/en/html/SG.html
- On TEI XML: http://www.tei-c.org/Support/Learn/tutorials.xml
- Additionally: Wieringa, Jeri. 2012. “Intro to Beautiful Soup.” Programming Historian, December. https://programminghistorian.org/lessons/intro-to-beautiful-soup.
- Additionally: Beals, M. H. 2016. “Transforming Data for Reuse and Re-Publication with XML and XSL.” Programming Historian, July. https://programminghistorian.org/lessons/transforming-xml-with-xsl.
Homework:
- Cleaning the “Dispatch”:
- write a python script that will create clean copies of text from each issue of the “Dispatch” that you scraped before (make sure to keep the originals intact!).
- write a python script that will create clean copies of articles (!) from all issues of the “Dispatch”. (again, make sure to keep the originals intact!).
- Publish an annotated text of your script on your website as a blogpost.
- Codecademy’s Learn Python, Unit 9-10.
- Github: publish the confirmation screenshot as a post on your new site.
Homework Solution:
Pseudocode (for 1b)
1. create `TargetFolder`
2. collect the `list_of_files` from `SourceFolder`
3. loop through the `list_of_files`
1. open each file (path: `SourceFolder`+`list_of_files`)
2. find `issue_date`
3. split the issue into `articles`
4. create `counter`
5. loop through `articles`
1. update `counter` (+1)
2. remove XML tags
3. do other cleaning, if necessary
4. create `fileName` = `issue_date` + `_` + `counter`
5. save text into a file: `TargetFolder` + `fileName`
NB: Pseudocode is a detailed yet readable description of what a computer program or algorithm must do, expressed in a formally-styled natural language rather than in the syntax of a programming language. Pseudocode is sometimes used as a detailed step in the process of developing a program. It allows designers or lead programmers to express the design in great detail and provides programmers a detailed template for the next step of writing code in a specific programming language. (adapted from here)
Python code (for 1b)
import re, os
source = "path_where_initial_files_are"
target = "path_to_save_new_files"
lof = os.listdir(source)
counter = 0 # general counter to keep track of the progress
for f in lof:
if f.startswith("dltext"): # fileName test
with open(source + f, "r", encoding="utf8") as f1:
text = f1.read()
# try to find the date
date = re.search(r'<date value="([\d-]+)"', text).group(1)
# splitting the issue into articles/items
split = re.split("<div3 ", text)
c = 0 # item counter
for s in split[1:]:
c += 1
s = "<div3 " + s # a step to restore the integrity of items
#input(s)
# try to find a unitType
try:
unitType = re.search(r'type="([^\"]+)"', s).group(1)
except:
unitType = "noType"
print(s)
# try to find a header
try:
header = re.search(r'<head>(.*)</head>', s).group(1)
header = re.sub("<[^<]+>", "", header)
except:
header = "NO HEADER"
print("\nNo header found!\n")
text = re.sub("<[^<]+>", "", s)
text = re.sub(" +\n|\n +", "\n", text)
text = re.sub("\n+", ";;; ", text)
# generating necessary bits
fName = date+"_"+unitType+"_"+str(c)
itemID = "#ID: " + date+"_"+unitType+"_"+str(c)
dateVar = "#DATE: " + date
unitType = "#TYPE: " + unitType
header = "#HEADER: " + header
text = "#TEXT: " + text
# creating a text variable
var = "\n".join([itemID,dateVar,unitType,header,text])
#input(var)
# saving
with open(target+fName+".txt", "w", encoding="utf8") as f9:
f9.write(var)
# count processed issues and print progress counter at every 100
counter += 1
if counter % 100 == 0:
print(counter)